亚bo体育网并且绕开了CUDA的截至以后-亚博买球 体验棒 官网入口

HuggingFace热点榜单险些被中国模子“承包”了!
在最新的HuggingFace热点模子榜单中,中国模子的含量跳跃了50%。包括刚刚上新的QwQ-32B不同型号的推理模子,HunyuanVideo-12V的全新版块、永久霸榜的DeepSeekR1,以及Qwen和R1的繁衍模子。
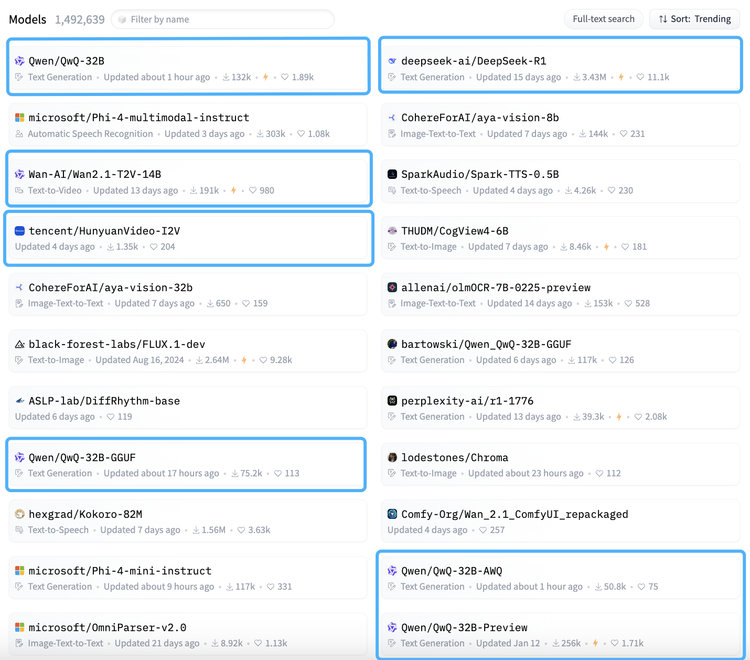
DeepSeek开源R1给通盘大模子行业扔下一颗炸弹,激发了模子社区和企业的热烈测度后,险些照旧细目了开源为主流技艺阶梯,此前一直坚捏闭源阶梯的如OpenAI、百度、月之暗面也接踵示意将尝试开源阶梯。
与以往不同的是,R1之后的冲榜不单体刻下数目多上,更体刻下质地上。“早期一些大厂的开源模子仅仅挂上去,后续不会再运营和难得,刻下在模子性能、实用性和褂讪性上都有冲破,并且绕开了CUDA的截至以后,对部署算力的要求更低,算是缓缓走出了零丁弧线。”一位开采者讲谈。
更值得谛视的是,越来越多国际开采者选拔中国基础模子当作微调发轫,比拟于Llama和Phi,以DeepSeek和Qwen系列模子为基点的繁衍模子越来越多。
咱们与多位开采者和企业聊了聊,为什么中国开源模子如斯受原宥?
第一部分:要作念就作念真开源
在选拔微调模子前,起初要关爱的就是开放左券。
中国开源模子基本上继承的都是最为宽松Apache 2.0开放左券或MIT左券,这意味着开采者不错开脱进行二次开采、商用,且基于这些模子开采的专利归开采者本东谈主通盘,灵验侧目了法律风险,为企业提供了细目性。
一位活跃于HuggingFace社区的资深开采者共享谈:“咱们团队领先仅仅试用Qwen系列,但很快发现其API瞎想和开源资源之完善超出预期。更瑕玷的是,咱们无须惦念改日倏得转变左券或截至使用,这种细目性对生意模样至关瑕玷。”
不少国际初创公司也提到中国模子相等故意的许可形式让他们有时平直使用,无需繁琐的法律审查。即等于离生意化最近的视频模子,Wan和HunyuanVideo除了需要征服相应的规定和截至条件,亦然不错免费商用的。比拟之下,Meta的Llama继承自主制定左券截至商用,且专利归原公司通盘,这无疑加多了开采者的法律牵挂。
当咱们顺手绽开HuggingFace中Llama模子的批驳区就会发现,在开采者测试中,屡次出现探询模子的申请被拒却的情况。这种不褂讪的探询体验,加上牵丝攀藤的使用条件,让很多开采者令人作呕。一位企业AI技艺矜重东谈主直言:“咱们不成基于一个随时可能被截至使用的模子来构建居品。”
其次,中国模子在开源深度上更进一步。不仅开放了从小到大等全系列不同参数规格的模子权重,还提供了多样量化版块和圆善的进修数据集,以致包括微调所需的数据模板。这种全面性让路发者有时凭证现实需乞降硬件条件选拔最相宜的版块。
“比如说适用于Qwen的编码数据集CodeAlpaca-20K,可在 Hugging Face 上不错平直找到。该数据集包含20000 条与编码关系的教导、输入和输出,不错得志基本的微调需求。”
这种透顶的开放作风也影响了最新的中国模子开源,当HunyuanVideo-12v版块开源时,相较于2个月前的版块,开放权重更高。模子总参数目保捏130亿,适用于多种类型的变装和场景,包括写实视频制作、动漫变装以致CGI变装制作的生成。开源内容包含权重、推理代码和LoRA进修代码,支捏开采者基于混元进修专属LoRA等繁衍模子。
另一方面,从模子自己起程,Llama3刻下仅提供8B、70B和405B三种规格,却零落被业内公以为算力与性能最好均衡点的32B参数限度。对大多数开采者而言,7B模子性能已不及以支捏复杂操纵,而70B以上则需要刚烈的工作器支捏,本钱不菲。Qwen系列在这方面迭代更快,规格隐痛更全面,从超轻量到分量级都有处分有计算。
一位国际开采者评价:“LLama3的迭代速率彰着慢于Qwen系列,尤其是模子参数目规格的隐痛进度更是存在弘远的短板,于今仍然莫得补皆。”
虽然,在性能方面,中国模子已与顶级闭源模子颠倒以致在某些边界迥殊。DeepSeek-R1自上线以来,照旧成为开源社区最受原宥的推理模子,最新评测数据线路,Qwen-72B模子照旧跳跃GPT4水平,而在处理汉文等特定任务时进展更佳。DeepSeek系列在代码生成智商上也得回了跳跃顶级模子的评分。
有开采者对比发现,透顶微调Qwen 1.5 0.5B模子比使用QLoRA对Phi 1.5进行微调的后果要好得多,且Phi的微调时辰要接近Qwen的5倍。
与其他打着“开源”旗子却建立诸多截至的模子不同,中国模子在开放进度和性能进展上找到了均衡,这正眩惑群众开采者加入这一世态。
第二部分:让咖啡店雇主都能跑大模子
由于好意思国对高端GPU的出口管制,迫使中国开采者从依赖硬件堆砌的传统旅途转向“算法优先”的翻新形式。这种“算力短缺倒逼算法升级”的逻辑,鼓励中国开源模子变成独有的竞争力:通过架构翻新与算法优化,在有限算力下达成可用性最大化,镌汰部署门槛,让咖啡店雇主都能跑大模子。
比如最新的QwQ-32B推理模子,险些透顶迥殊了OpenAI-o1-mini,远胜于o1-mini及相易尺寸的R1蒸馏模子,在保捏性能的前提下把模子作念小到32B的最好部署参数区间,是呈现出来的一个趋势。
“骨子上是用算法复杂度置换高算力需求,当模子参数目镌汰两个数目级时,进修所需的显存从千兆字节级压缩至浮滥级显卡可承载的96GB以内,大模子的部署不再依赖专科诡计集群。”
参数变小后再通过特定的算法镌汰内存和对显存的需求,QwQ-32B在浮滥级显卡4090或一台装备M4芯片的MacBook上就能完成部署。
再比如视频生成类模子HunyuanVideo-12V和Wan2.1版块,也可在T2V-1.3B 型号仅需 8.19 GB VRAM,可兼容险些通盘浮滥级 GPU。可在约 4 分钟内(未使用量化等优化技艺)在 RTX 4090 上生成 5 秒的 480P 视频。
另外一方面,是中国大模子照旧透顶耕作起了开放生态,开源程序得到了第三方模样和器具的世俗支捏。

在进修和微调方面,多个开源框架为中国大模子提供了刚烈支捏。举例,DeepSpeed Chat 提供了一键式RLHF(基于东谈主类响应的强化学习)进修框架,支捏从数据预处理到模子评估的圆善进修进程,权贵镌汰了复杂任务的开采门槛。
此外,LLaMA Efficient Tuning 提供了基于PEFT(参数高效微调技艺)的微调框架,支捏LoRA、Adapter等多种微调形式,使开采者有时以更低的诡计本钱达成模子性能的优化。这些开源器具不仅隐痛了从预进修到微调的全进程,还通过模块化瞎想提高了天真性和易用性,为开采者提供了丰富的选拔。
在模子推理方面,雷同有多种高效框架支捏中国大模子的部署。举例,vLLM 针对大都量Prompt输入场景进行了优化,通过动态内存照管和高效调遣算法,权贵进步了推理速率和蒙眬量。而 Xinference 则是一个功能全面的散布式推理框架,支捏多节点并行诡计,简化了空话语模子的部署进程,尤其相宜高并发、低蔓延的操纵场景。
这些框架与中国大模子(如Qwen、DeepSeek等)透顶适配,不仅进步了推理遵循,还镌汰了硬件资源需求,使得模子的部署愈加节略和经济。
模子最开放、型号最全亚bo体育网,与开放生态器具透顶耦合,同期兼具着最低的部署门槛,使更多开采者有时参与试用,来自中国厂商的这么的开源模子还会越来越多,一个全新的生态结构正在安祥耕作起来。
